第三章——VC-Dimension
本系列是根据台大林轩田老师的《机器学习基石》中的课程内容整理及一些个人的理解与见解。如有错误之处,还请各位通过我的个人邮箱: 756161569@qq.com 联系我、批评指正,感谢!
在第一章中我们利用的霍夫丁不等式证明了机器学习在测试样本与训练样本中的表现(误差)会小于一个特定的值。但是我们并没有完全交代清楚这个上界有多大,今天我们就来对这一块做近一步的分析。
还是从霍夫丁不等式说起
在第一章里我们就是通过这样一个不等式得出”只要在训练数据量足够大的情况下,测试样本与训练样本的误差将会非常小”的结论。(其中N为样本数量,\(\varepsilon\) 为误差。)
但这个不等式只代表了一个H(x),也就是众多 Hypothesis 中的一个,我们知道,Hypothesis可能是无穷多个,我们假设这个Hypothesis一共有M个H(x),而且这些H(x)之间互相独立。那么P[BAD]就等于这M个误差的和,也就是
那这样问题就来了,请看原文PPT: 
这页PPT主要向我们说明一个问题,当M很小的时候,P[BAD]也会很小,但是但是我们可选择的H也会很少;当M很大的时候,我们可选择的H多了,但是我们却不能保证P[BAD]很小。
Hypothesis数量的上限
我们再来回忆一下M是怎么来的,我们假设了Hypothesis的个数是M,并且假定了他们之间是没有关联的,所以我们将所有Hypothesis的BAD情况相加得到了最终的M。
但实际情况却不是这样的,众多Hypothesis之间存在很大的重复性。
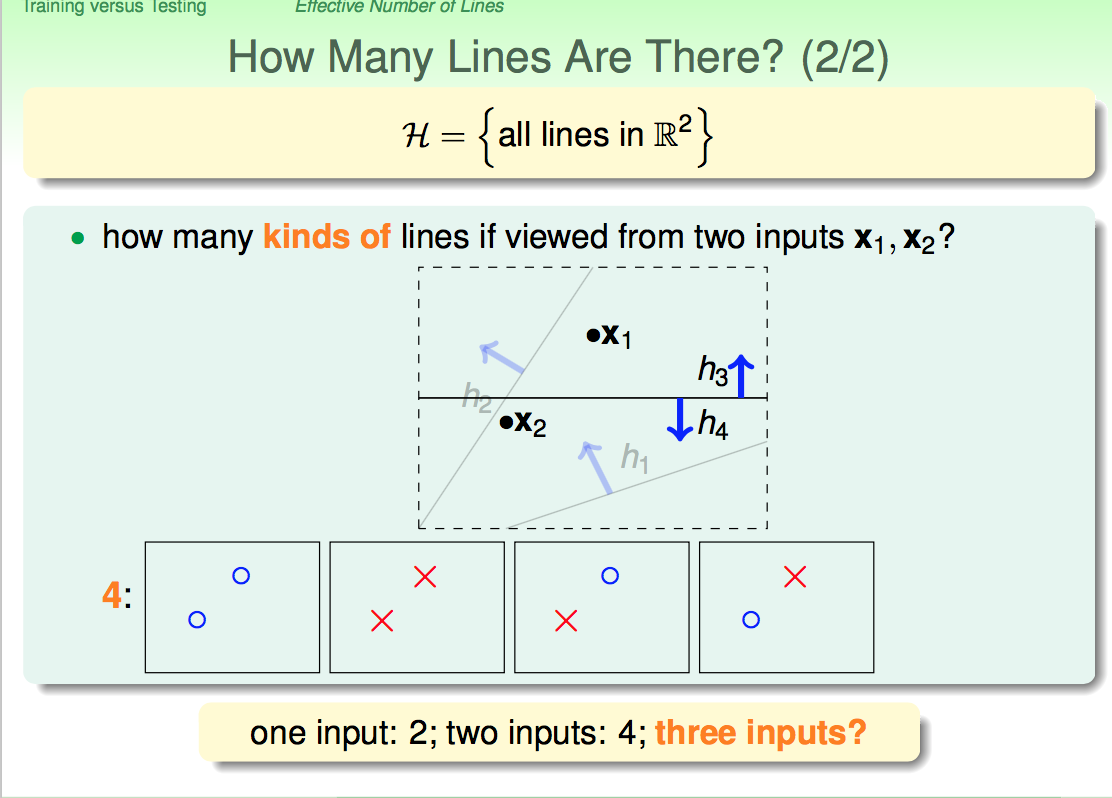
如上图所示,图中有X1、X2两个点,我们需要一条直线去将他们区分开。众所周知,一个平面内有N条直线,但是这些直线最终能被归为4”类”。(类代表他们最终将X1、X2分类的效果是一样的)
所以,我们确定Hypothesis之间并不是没有关联的,相反,大多数Hypothesis是重合的。所以,我们需要一个\(H_M\)函数来表示M的上界。
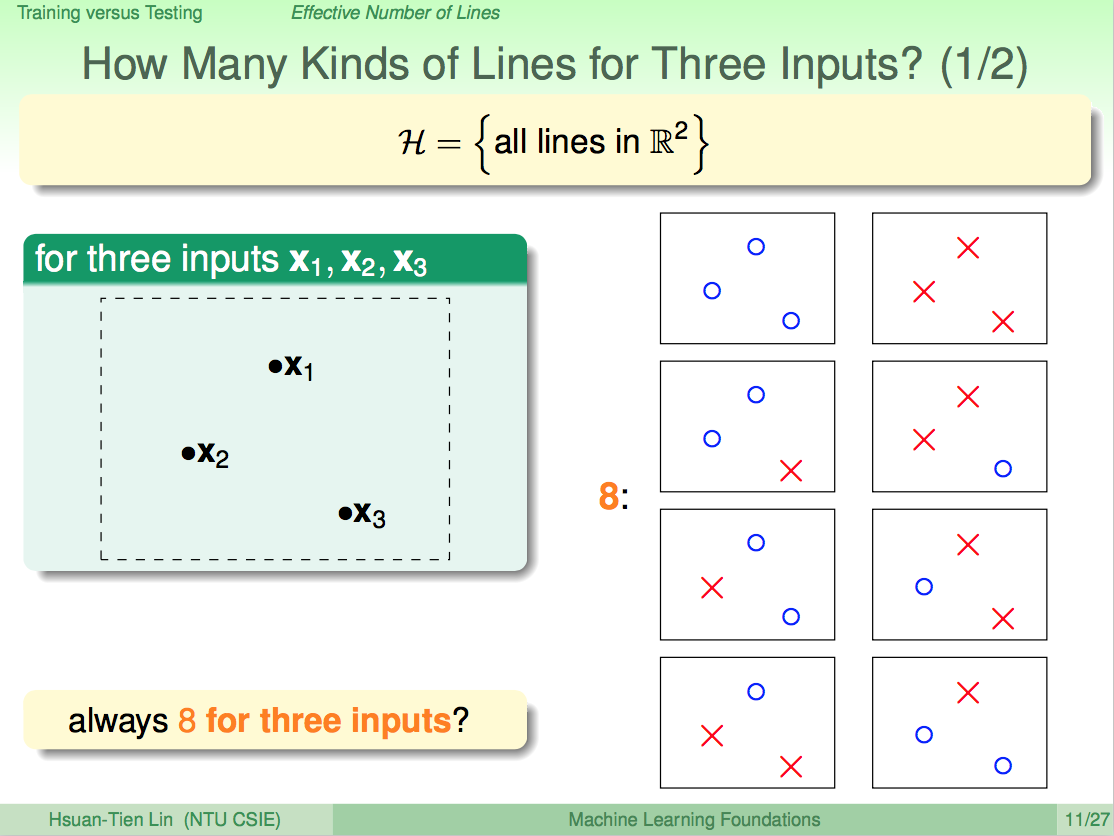
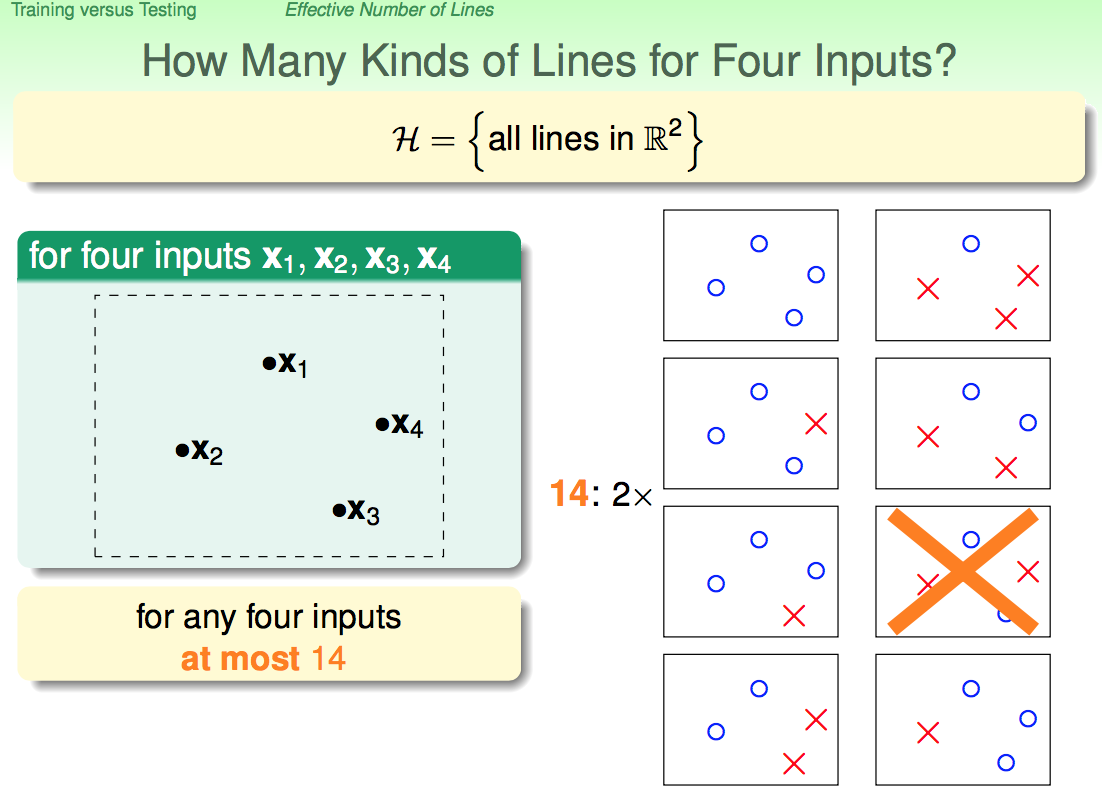
从上面两张图中我们可以看出,当点的个数是3个时,一共有8种区分情况;当点的个数是4个时,一共有14种情况……
我们用effective(N)来表示这些”有影响的”Hypothesis,那么最初的错误公式就变成了:
并且我们能够得出:
Growth Functions
上面我们刚刚用effective(N)代替了M,并且得出了effective(N)的上限,但很明显影响最终分类个数的不仅仅有N,还有做分类的模型本身的性质。也就是Hypothesis。
所以,我们引出一个 成长函数(Growth Functions)的概念,用来表示一组Hypothesis Set作用在资料量为N的资料上所能产生的最多分类类别。
以下是几种常见的Hypothesis Set的成长函数。
1.Positive Rays


Positive Rays 代表是在一维空间下 阈值为a(大于a输出+1,反之输出-1)的情况下,所能出现的分类类别。
图中我们可以看出,当N=4时,一共能产生5中分类,所以:
2.Positive Intervals

Positive Intervals 代表是在一维空间下,有两个阈值,加载他们中间是+1,其余为-1。

由上面的图中可以得知,当N=4时,一共有11中分类类别,所以:
3.Convex Sets
任选k个点,在这k个点组成的convex多边形包围内的所有点都预测+1,否则预测-1。
这种情况就是最坏的情况,因为m就是最大上限2的N次方。
Break Point
上一节我们分析了最常见的三种Hypothesis Set的成长函数,并且得出了他们关于N的成长函数计算公式。这一节我们再引入一个新的概念——break Point。
我们定义存在最小的N,使得:
那么我们就称这个N为该函数的Break Ponit。
假如不存在这个点,那么我们就称N个inputs被H给shatter掉了。
那么这个Break Point有什么用呢?
如果一个函数不存在Break Point,那么这个函数的成长函数就是2的N次方。那么如果在数据量N特别特别大的时候,成长函数也会特别大,这显然不是我们想看到的。
如果存在这个Break Point,事情就不一样了,我们的成长函数上界就有可能缩的非常小,使得文章最开始的霍夫丁不等式能够满足N特别大,M特别大的时候,”坏情况”也能收敛在一个相对较小的值。
那么出现Break Point以后,成长函数的上界又是什么样的呢?它能缩小到多小呢?
Restriction of Break Point
我们知道Break Point出现以后,成长函数也就会出现上界,那么我们能不能求出Break Point出现以后,成长函数上界与这个Break Point的关系函数呢?

让我们先看上面图。我们约定Break Point=2,N=3。
上图中被划上红线的一组情况为什么不能被加入所有可能的分类情况呢?
因为Break Point=2的时候就代表了任意两个点都不能被shatter(\(m_{H}(N) = 2^{N}\)),但图中如果加入第四个情况的话,X2、X3这一组就会被shatter。
同样的,以下两种情况也不能加入。


找到了Break Point出现的意义以及影响以后,我们再来分析他们的规律。
我们用B(N,k)来表示break point为k的任意的H作用于size为N的任意的D所能产生的dichotomies的数量的上限。
所以,由上图我们可以得知B(2,2)=3; B(3,2)=4。
我们可以轻易得出以下结论:
- k=1时,1个点都没有办法shatter,因此B(?,1)恒等于1。
- k>N时,H一定能shatter掉N个点,因此它产生的dichotomies的种类等于这N个点所有的排列组合数
- k=N时,从\(2^{N}\)个排列组合中移除掉一个,剩下的都可以作为dichotomies,因此它产生的dichotomies的数量“最多最多”可以是\(2^{N}-1\)。
根据以上规律,我们可以得出下面这张表: 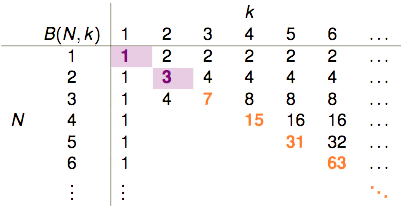
总结图中的规律,我们不难得出:
运用数学归纳法,我们可以证明:
如果以2D Perceptrons为例,当Break Point为4的时候,他的成长函数上界为:
这可比2的N次方小多了!
总结
文章最开始,我们引入Hypothesis Set可能是无限多的,所以我们可能并不能找到一个很好的f。
由于Hypothesis Set的数量M可能是无限多个,所以我们转而求有效的Hypothesis Set(effective(N)),知道了effective(N)一定会小于2的N次方。
然后我们再用成长函数\(m_{H}\)来表示effective(N),然后发现存在Break Ponit的时候,成长函数也存在一个明显的上界。
总结来讲我们这一章所做的事情就是得出上面的公式,然后证明这个公式能在某一个较小的值下收敛,也就是出现坏情况的概率较小。