神经网络训练的训练技巧(一)
学完理论原理以后,我们再来看看如何在实战中获得更好的模型
深度学习中的常见问题
偏差与方差
在进行神经网络训练过程是一个不断迭代、调优参数的过程,但如何去判定一个神经网络的好坏呢?
首先我们先介绍两个名词: 偏差(Bias)、方差(Variance)
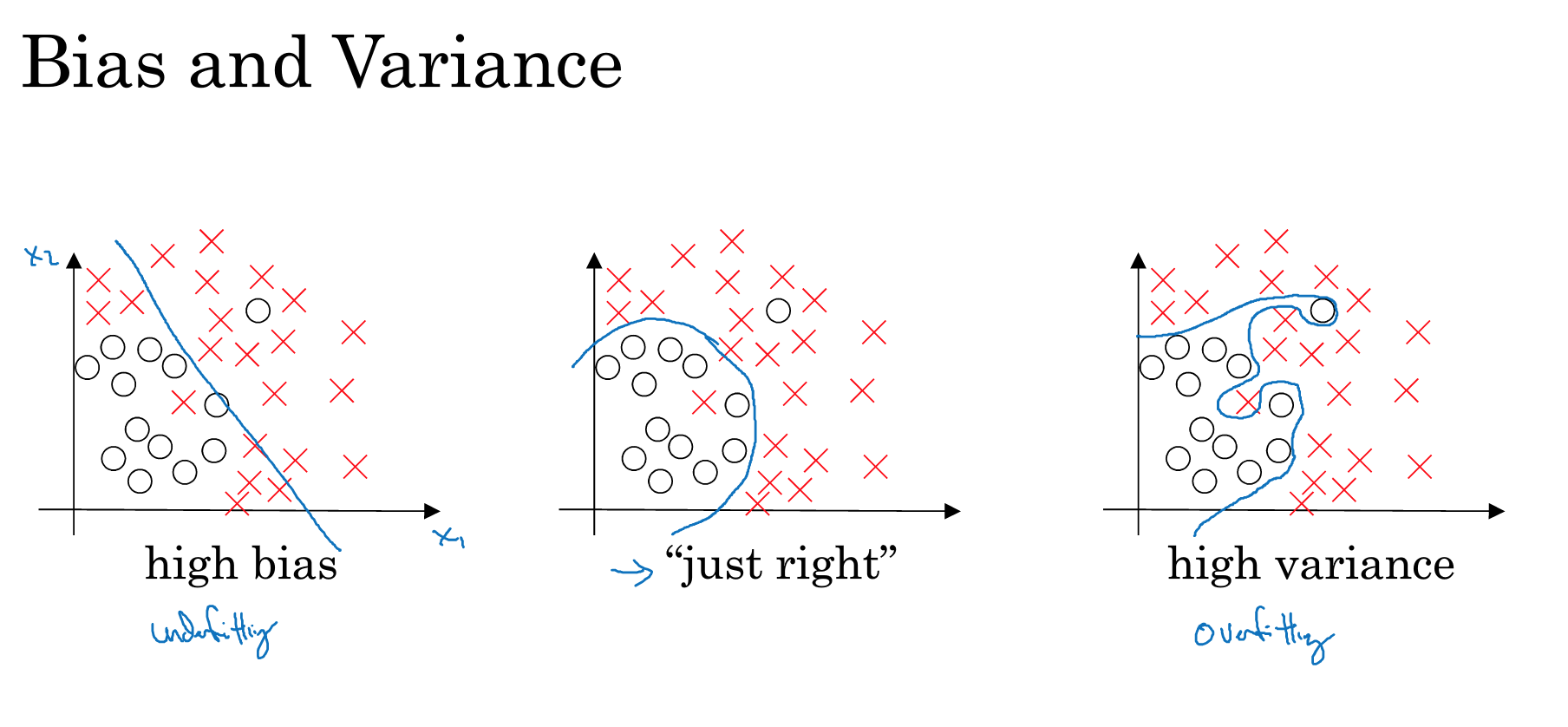
如上图所示,我们的目标是对圈圈和叉叉进行分类,蓝色的线就是我们的分类线。
图中可以看出,最左边的线在区分上明显正确率不够(很多叉叉被错误的分类成了圈圈)。我们称这样的情况是欠拟合(under-fitting) 。也可以称之为 高偏差(high bias)
对应的,在最右边的图中,模型虽然完全正确的分类了。但很明显,模型太过复杂,很难应用到测试数据集,因此我们称之为过拟合(over-fitting),或者高方差(hige variance)
很明显,中间的模型更优质,虽然它并没有作出完全正确的分类,但很明显它在高偏差和高方差之前做了很好的平衡。所以,我们训练的目标就是使bias和variance变得尽量平衡、尽量小。
数据集划分
上文中讨论的高方差其实还有一个先决条件,那就是我们的训练集和测试集必须取自相同分布的原始数据。
如果他们取自不同的数据源,或者他们的分布存在明显的差异,那么variance将变得没有太大的参考价值。
为了满足这一要求,我们将数据集随机切分成3块——Train、Dev、Test。
其中Train就是我们训练时使用的数据集;Dev是为了方便我们做交叉验证的数据集;而Test是我们做最终模型评估的数据集。
| Data Size | Train | Dev | Test |
|---|---|---|---|
| 10,000 | 60% | 20% | 20% |
| 10,000,000,000 | 98% | 1% | 1% |
| more | 99% | 0.5% | 0.5% |
上图是在不同数据量的情况下对三个数据集拆分的比例。当数据集很大时,交叉验证是非常耗时的,所以留出1%即可。当数据量继续变大时,Dev、Test的比例还可以缩小。
如何解决过拟合
正则化
在深度学习的过程中,如果bias偏大,那我们只需要让加深神经网络的深度或者增加隐藏层的单元数即可。
但处理过拟合的问题则就需要其他比较复杂的处理了,而正则化就是其中一种。
什么是正则化呢?
其实就是在原先的损失函数上加上一个和W有关的正值。
以下是几个常见的正则化L1、L2正则化的表达式:
L2正则化(最常使用):
L1正则化:
正则化为什么可以解决过拟合问题
从损失函数角度
如上文所述,L2正则化是在损失函数J的基础上加上W矩阵的2范数。假如 \(\lambda\)特别大,那么在获得同样小的损失函数J的时候,W矩阵就会趋向于0。
权重矩阵W趋向于0并不代表W所代表的神经单元消失了,而是指W的每个单元对最终决策的影响都变小了。
从激活函数的角度
大家再回忆一下神经网络单元的计算规则:
如果W变小了,那么最终结果Z也会变小。我们再来看下激活函数tanh函数: 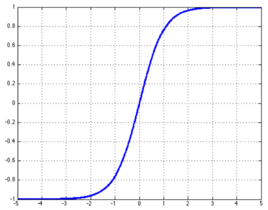
如果Z很小,Z就会落在激活函数相对”陡峭”的位置,也就是接近线性函数的模型。
大家还记得为什么激活函数一定要是非线性的吗?因为如果激活函数是线性的,那么无论网络有多深,都只能解决线性问题。
因此,将Z限定在接近线性函数模型的区域可以很大程度降低激活函数对最终模型的影响,从而达到解决过拟合的问题。
Dropout Regulazation
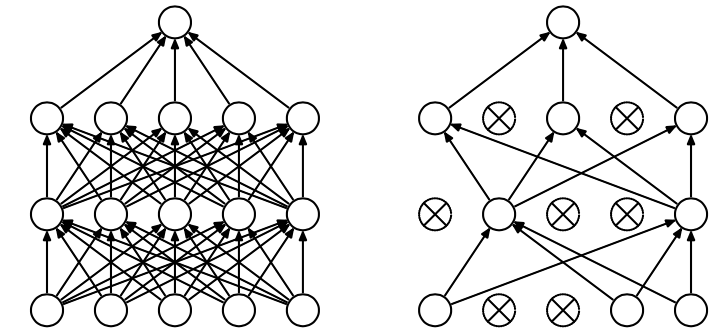
本文暂时不深入分析该算法,暂时只对改算法的思想做一部分阐述,如果想进一步了解请看这里。
如上图所示,左边的图就是一个正常的神经网络图,而右图就是Dropout思想下的神经网络。
其实归根结底,神经网络的过拟合无非是网络太深或者隐藏层的节点太多,Dropout正式针对这一点的优化。
可以看出,Dropout在一个N * N的网络上随机去掉了部分点(这与上文的正则化不一样)。也就是通过降低网络的复杂度来解决过拟合的问题。
优化训练
正则化输入
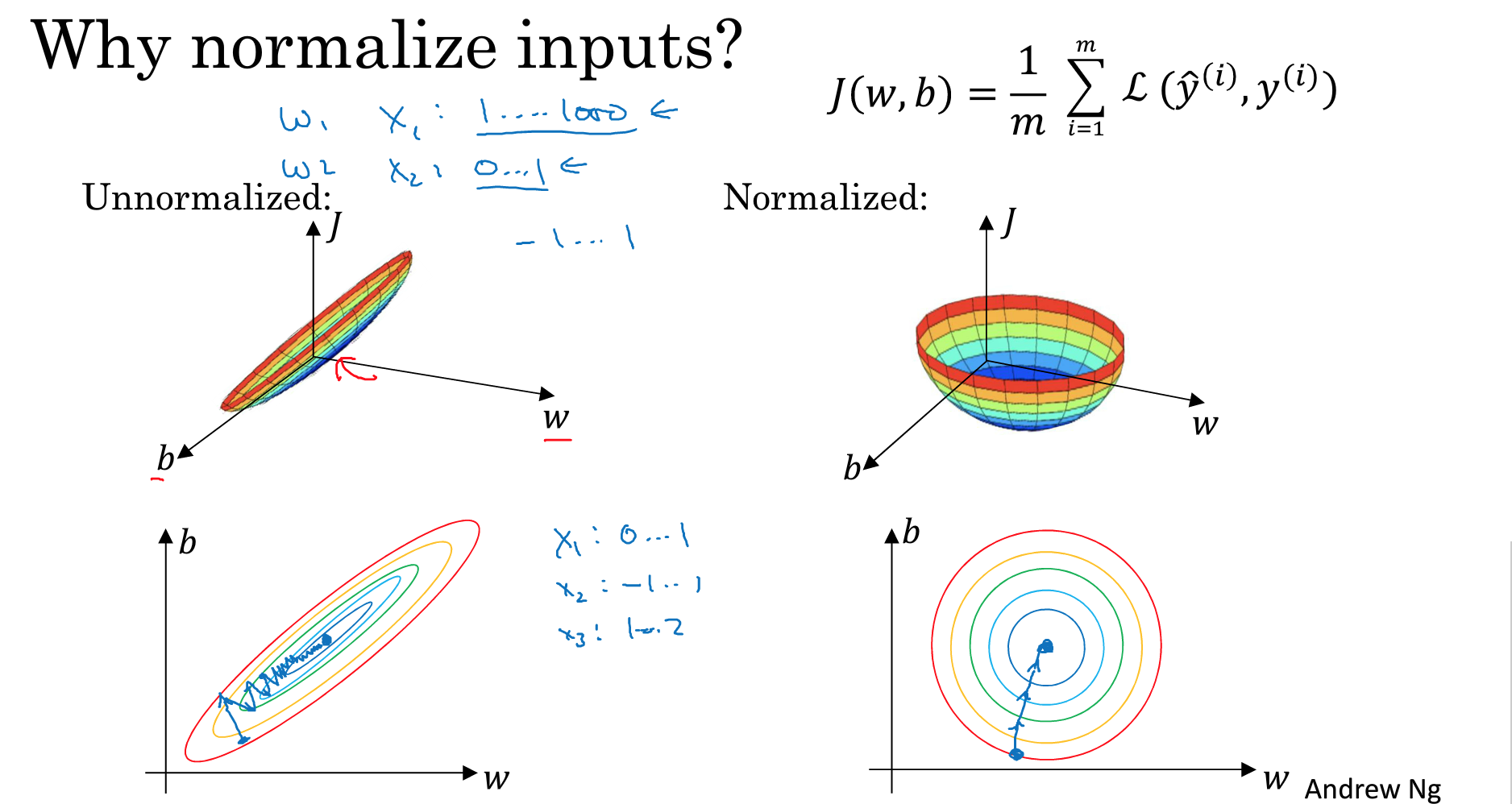
上图中的左边代表了维度单位差别很大的输入参数图以及梯度下降过程中的路径,而右边则是经过正则化输入的。
根据梯度下降的轨迹可以看出,正则化输入以后的梯度下降轨迹是直奔最低点。而相对而言,原始输入数据的梯度下降轨迹要显得更加曲折。
所以,当各个特征维度的数据不均衡的时候,梯度下降的速度要明显慢于一个经过正则化以后的数据。
梯度消失与梯度爆炸
关于这部分的讨论比较复杂,今后可以单独抽出一篇博文。本文暂时只做直观上的解释,详细解释请参考详解机器学习中的梯度消失、爆炸原因及其解决方法。这一小节的图片也来源于这篇文章。
梯度爆炸简单来讲就是在一个深层次的神经网络训练过程中由于权重更新时链式求导,这个时候会涉及对前层的激活函数求导。如果前层的激活函数导数和1差距很大,那么在进过很多层的链式求导以后就会导致一个类似滚雪球的效应,使得更新越来越大或者越来越小,也就是常说的梯度消失/梯度爆炸。
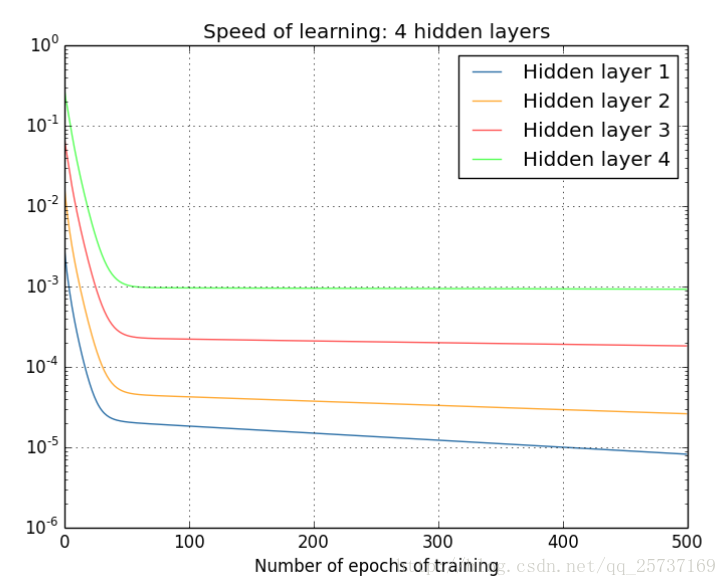
上图描述的是不同深度的网络层的训练速度,我们可以看出,越是远离输入层的权重更新越是慢。这里就可以说是发生的梯度消失。
还有一个原因就是针对激活函数:
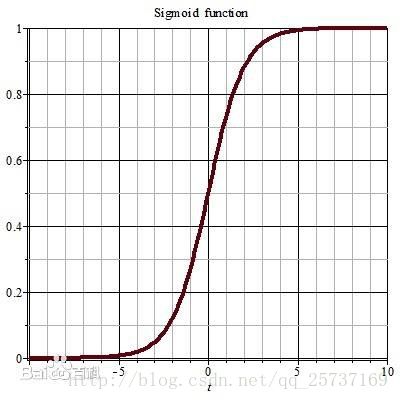
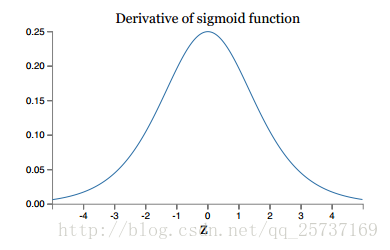
上图分别是sigmoid函数的函数模型以及其导数的函数模型。因为在进行权重更新的时候需要计算前层偏导,但关于sigmoid的梯度是不可能超过0.25的,所以非常容易发生梯度消失。
目前主要的解决方案重点在于优化激活函数,比如用leakrelu、elu等激活函数代替sigmoid函数。
还有一个很著名的解决方案就是LSTM长短期记忆网络(long-short term memory networks)。感兴趣的同学可以继续深入研究。