神经网络训练的训练技巧(二)
上一篇我们提到了深度学习中常见的一些问题,例如拟合问题和优化问题,这一篇我们谈一谈如何优化神经网络的训练。
优化训练
Mini-batch 梯度下降
如果你看过本系列第一篇文章神经网络训练的理论推导 你就会意识到整个神经网络的训练过程就是根据损失函数做梯度下降,直到找到那个让损失函数值最小的模型。
理论上我们只需要将所有的输入构造成一个输入矩阵,然后迭代更新权重矩阵W和偏移量b就行。
但是在实际的生产应用过程中,我们的数据量是非常大的,而矩阵的运算又是特别耗费CPU(GPU)的,所以我们不太可能一次性将所有输入数据全部喂给神经网络。
关于计算机工程的一些说明:
一般的应用服务器256G的内存可以说是超大内存了,而且价格非常之高,现在针对深度学习开发的GPU价格也是高的吓人,所以在实际的生产的过程中我们不太可能用一个”超级计算机”去帮我们训练神经网络。试想一下,加入我们有1个T的数据,我们在训练的时候就需要将这一个T的数据全部装载到内存……这么大的内存反正我是没见过。
而且,即使我们有这么样一个超级计算机,在计算机工程领域也是不合理的。因为这样的计算太耗时,而且非常不稳定,举一个最简单的例子,假如你训练到一半机房断电,那么你所有的工作都得全部重来。没错,就是那么悲剧~
所以,在工程上,我们往往用很多廉价的机器去代替所谓的”超级计算机”,也就是所谓的分布式计算。
我们将任务分成很多很多个批次,以快速迭代、分批次并行的方式处理我们的数据。这样,即使我们其中某些批次执行失败了,我们只需要重新跑那几个小的批次就行。这样计算的时间和出错的概率将会大大降低。
有了计算机工程上的支撑,那么我们就可以对我们的神经网络训练也做对应的优化。
所以Mini-batch 梯度下降说白了就是对输入数据的批次拆分,然后将这些拆分好的数据一个批次一个批次的喂给神经网络。
当然了,对Mini-batch的拆分既不能太大也不能太小,太大了和直接梯度下降差别不大;太小了又会导致训练的方向剧烈抖动,导致梯度下降效果不佳。
吴恩达老师给出的训练批次大小建议是一般64-512。当然了,这些都是需要你在实战中根据硬件的配置、计算的耗时等去综合调节的。
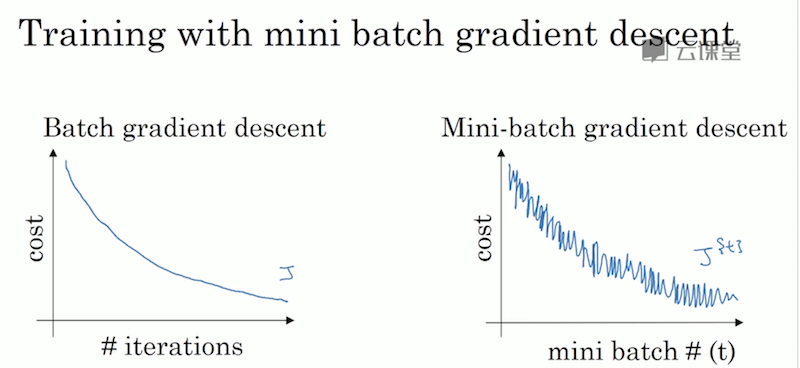
最后,给一张吴恩达老师给出的训练过程示意图,描述了普通训练和Mini-batch训练关于cost function的变化轨迹。
动量梯度下降、RMSprop
大家可以看到上图梯度下降过程中cost function一直处于”抖动下降”的趋势。也就是说每次Mini-batch梯度下降并不都是朝着下降最快的方向去的(从全局角度看)。
所以,我们需要想办法减小这种”抖动”,让梯度下降更加”平滑”,从减少cost function到达目标点的迭代次数。
做到这一点就需要先了解下面这个概念。
指数加权平均
先给出公式:
我们以t日内的温度来解释它。
其中\(\beta\)是一个全局参数,\(\nu_{t-1}\)代表t-1日的温度指数,\(\Theta_{t}\)表示第t日的温度。
我们对这个公式做一个实例化的解释(假设\(\beta\)=0.9):
从上面公式不难看出,指数\(\nu\)其实考虑了\(\Theta_{0}-\Theta_{t}\),只是与t越接近对\(\nu\)的影响就比较大,反之影响就比较小。
这样做的意义是什么呢?
我们常常会因为某一天的气温异常而导致整个曲线看上去不够平滑,但如果忽略这些(或者说平滑)异常点,并不影响我们对整体趋势的预测和把握。
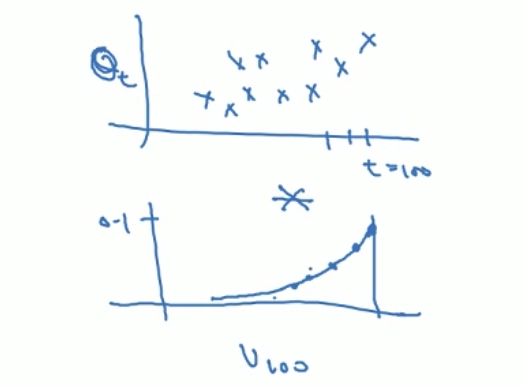
上图就是以\(\Theta\)为纵轴和以\(\nu\)为纵轴的区别,不难发现以\(\Theta\)为纵轴不仅保留了原始的趋势,同样也更加平滑。
正是因为这样的特性,我们才将他运用到神经网络的训练中来,利用它的这种特性去让神经网络梯度下降的过程更加平滑,进而达到提升训练效率的目的。
动量梯度下降
讲明白了指数加权平均,在看动量梯度下降就简单了。
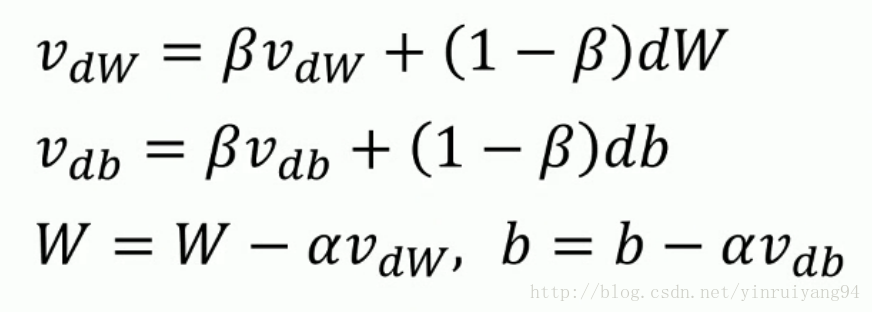
我们原先梯度下降是根据偏导去更新W/b的,现在我们先对偏导做一个指数加权平均,也就是平滑一下它的下降方向,再更新权重。
RMSprop
RMSprop 其实和动量梯度下降大同小异,核心原理都是指数加权平均。

它与动量梯度下降的区别主要体现在对权重更新的方式上,所以我把他们放在一起讨论。
具体的数学证明就不给出了,我们直接看效果。上图不难看出,梯度下降在无关方向上的抖动幅度更小了,更加”直接”的逼近最佳点。
Adam

理解了上面两个优化算法,理解Adam就更加简单了——Adam我个人理解是对动量梯度下降和RMSprop的结合。因为它既要计算动量梯度下降指数\(\nu\)也要计算RMSprop指数S,并在更新W的方式上结合了这两个指数。
总结来讲,整个优化算法的核心思想就是:
- 以小批次分布更新替代大批量更新。
- 根据指数加权平均的原理,平滑梯度下降,减小梯度下降的”抖动”幅度。